CMS Data Analysis School Tracking and Vertexing Short Exercise - The five basic track variables
Overview
Teaching: 15 min
Exercises: 15 minQuestions
What are the main track variables used in CMS collaboration in different data formats?
How can we access them?
Which are the track quality variables?
How do the distributions of track variables before and after high purity track selection change?
Objectives
Being familiar with tracks collections and their variables.
Being aware of track information stored in different data format.
Accessing information and plot basic variables using ROOT.
One of the oldest tricks in particle physics is to put a track-measuring device in a strong, roughly uniform magnetic field so that the tracks curve with a radius proportional to their momenta (see derivation). Apart from energy loss and magnetic field inhomogeneities, the particles’ trajectories are helices. This allows us to measure a dynamic property (momentum) from a geometric property (radius of curvature).
A helical trajectory can be expressed by five parameters, but the parameterization is not unique. Given one parameterization, we can always re-express the same trajectory in another parameterization. Many of the data fields in a CMSSW reco::Track are alternate ways of expressing the same thing, and there are functions for changing the reference point from which the parameters are expressed. (For a much more detailed description, see this page.)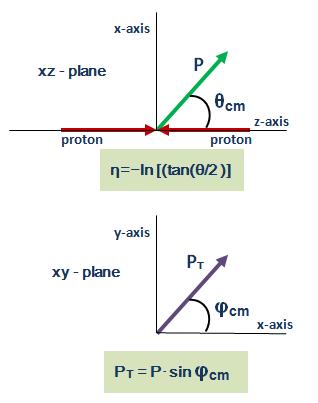
The five basic track parameters
signed radius of curvature (units of cm), which is proportional to particle charge divided by the transverse momentum, pT (units of GeV);
angle of the trajectory at a given point on the helix, in the plane transverse to the beamline (usually called φ);
angle of the trajectory at a given point on the helix with respect to the beamline (θ, or equivalently λ = π/2 - θ), which is usually expressed in terms of pseudorapidity (η = −ln(tan(θ/2)));
offset or impact parameter relative to some reference point (usually the beamspot or a selected primary vertex), in the plane transverse to the beamline (usually called dxy);
impact parameter relative to a reference point (beamspot or a selected primary vertex), along the beamline (usually called dz).
The exact definitions are given in the reco::TrackBase header file. This is also where most tracking variables and functions are defined. The rest are in the reco::Track header file, but most data fields in the latter are accessible only in RECO (full data record), not AOD/MiniAOD/NanoAOD (the subsets that are available to physics analyses).
Accessing track variables
Create print.py (for example emacs -nw print.py, or use your favorite text editor) in TrackingShortExercize/, then copy-paste the following code and run it (python print.py). Please note, if your run321457_ZeroBias_AOD.root is not in the directory you’re working from, be sure to use the appropriate path in line 2.
import DataFormats.FWLite as fwlite
events = fwlite.Events("file:run321167_ZeroBias_AOD.root")
tracks = fwlite.Handle("std::vector<reco::Track>")
for i, event in enumerate(events):
if i >= 5: break # print info only about the first 5 events
print "Event", i
event.getByLabel("generalTracks", tracks)
for j, track in enumerate(tracks.product()):
print " Track", j,
print "\t charge/pT: %.3f" %(track.charge()/track.pt()),
print "\t phi: %.3f" %track.phi(),
print "\t eta: %.3f" %track.eta(),
print "\t dxy: %.4f" %track.dxy(),
print "\t dz: %.4f" %track.dz()
The first three lines load the FWLite framework, the .root data file, and prepare a Handle for the track collection using its full C++ name (std::vector). In each event, we load the tracks labeled generalTracks and loop over them, printing out the five basic track variables for each. The C++ equivalent of this is hidden below (longer and more difficult to write and compile, but faster to execute on large datasets) and is optional for this entire short exercise.
C++ version
cd ${CMSSW_BASE}/src mkdir MyDirectory cd MyDirectory mkedanlzr PrintOutTracks cd ..Use your favorite editor to add (if missing) the following line at the top of
MyDirectory/PrintOutTracks/plugins/BuildFile.xml(e.g.emacs -nw MyDirectory/PrintOutTracks/plugins/BuildFile.xml):<use name="DataFormats/TrackReco"/>Now edit
MyDirectory/PrintOutTracks/plugins/PrintOutTracks.ccand put (if missing) the following in the#includesection:#include <iostream> #include "DataFormats/TrackReco/interface/Track.h" #include "DataFormats/TrackReco/interface/TrackFwd.h" #include "FWCore/Utilities/interface/InputTag.h"Inside the
PrintOutTracksclass definition (one line below the member data comment, before the};), replaceedm::EDGetTokenT<TrackCollection> tracksToken_;with:edm::EDGetTokenT<edm::View<reco::Track> > tracksToken_; //used to select which tracks to read from configuration file int indexEvent_;Inside the
PrintOutTracks::PrintOutTracks(const edm::ParameterSet& iConfig)constructor before the{, modify the consumes statement to read:: tracksToken_(consumes<edm::View<reco::Track> >(iConfig.getUntrackedParameter<edm::InputTag>("tracks", edm::InputTag("generalTracks")) ))after the
//now do what ever initialization is neededcomment:indexEvent_ = 0;Put the following inside the
PrintOutTracks::analyzemethod:std::cout << "Event " << indexEvent_ << std::endl; edm::Handle<edm::View<reco::Track> > trackHandle; iEvent.getByToken(tracksToken_, trackHandle); if ( !trackHandle.isValid() ) return; const edm::View<reco::Track>& tracks = *trackHandle; size_t iTrack = 0; for ( auto track : tracks ) { std::cout << " Track " << iTrack << " " << track.charge()/track.pt() << " " << track.phi() << " " << track.eta() << " " << track.dxy() << " " << track.dz() << std::endl; iTrack++; } ++indexEvent_;Now compile it by running:
scram build -j 4Go back to
TrackingShortExercize/and create a CMSSW configuration file namedrun_cfg.py(emacs -nw run_cfg.py):import FWCore.ParameterSet.Config as cms process = cms.Process("RUN") process.source = cms.Source("PoolSource", fileNames = cms.untracked.vstring("file:run321167_ZeroBias_AOD.root")) process.maxEvents = cms.untracked.PSet(input = cms.untracked.int32(5)) process.MessageLogger = cms.Service("MessageLogger", destinations = cms.untracked.vstring("cout"), cout = cms.untracked.PSet(threshold = cms.untracked.string("ERROR"))) process.PrintOutTracks = cms.EDAnalyzer("PrintOutTracks") process.PrintOutTracks.tracks = cms.untracked.InputTag("generalTracks") process.path = cms.Path(process.PrintOutTracks)And, finally, run it with:
cmsRun run_cfg.pyThis will produce the same output as the Python script, but it can be used on huge datasets. Though the language is different, notice that C++ and
FWLiteuse the same names for member functions:charge(),pt(),phi(),eta(),dxy(), anddz(). That is intentional: you can learn what kinds of data are available with interactiveFWLiteand then use the same access methods when writing GRID jobs. There is another way to accessFWLitewith ROOT’s C++-like syntax.The plugin is here:
/eos/uscms/store/user/cmsdas/2023/short_exercises/trackingvertexing/MyDirectory/PrintOutTracks/plugins/PrintOutTracks.ccTherun_cfg.pyis here:/eos/uscms/store/user/cmsdas/2023/short_exercises/trackingvertexing/run_cfg.py
Track quality variables
The first thing you should notice is that each event has hundreds of tracks. That is because hadronic collisions produce large numbers of particles and generalTracks is the broadest collection of tracks identified by CMSSW reconstruction. Some of these tracks are not real (ghosts, duplicates, noise…) and a good analysis should define quality cuts to select tracks requiring a certain quality.
Some analyses remove spurious tracks by requiring them to come from the beamspot (small dxy, dz). Some require high-momentum (usually high transverse momentum, pT), but that would be a bad idea in a search for decays with a small mass difference such as ψ’ → J/ψ π+π-. In general, each analysis group should review their own needs and ask the Tracking POG about standard selections.
Some of these standard selections have been encoded into a quality flag with three categories: loose, tight, and highPurity. All tracks delivered to the analyzers are at least loose, tight is a subset of these that are more likely to be real, and highPurity is a subset of tight with even stricter requirements. There is a trade-off: loose tracks have high efficiency but also high backgrounds, highPurity has slightly lower efficiency but much lower backgrounds, and tight is in between (see also the plots below). As of CMSSW 7.4, these are all calculated using MVAs (MultiVariate Analysis techniques) for the various iterations. In addition to the status bits, it’s also possible to access the MVA values directly.
Plot of Efficiency vs Eta:

Plot of Efficiency vs pT:

Plot of Backgrounds vs Eta:

Plot of Backgrounds vs pT:

Update the (create a new) print.py file with the following lines:
Add a Handle to the MVA values:
import DataFormats.FWLite as fwlite
events = fwlite.Events("file:run321167_ZeroBias_AOD.root")
tracks = fwlite.Handle("std::vector<reco::Track>")
MVAs = fwlite.Handle("std::vector<float>")
The event loop should be updated to this:
for i, event in enumerate(events):
if i >= 5: break # only the first 5 events
print "Event", i
event.getByLabel("generalTracks", tracks)
event.getByLabel("generalTracks", "MVAValues", MVAs)
numTotal = tracks.product().size()
if numTotal == 0: continue
numLoose = 0
numTight = 0
numHighPurity = 0
for j, (track, mva) in enumerate(zip(tracks.product(), MVAs.product())):
if track.quality(track.qualityByName("loose")): numLoose += 1
if track.quality(track.qualityByName("tight")): numTight += 1
if track.quality(track.qualityByName("highPurity")): numHighPurity += 1
print " Track", j,
print "\t charge/pT: %.3f" %(track.charge()/track.pt()),
print "\t phi: %.3f" %track.phi(),
print "\t eta: %.3f" %track.eta(),
print "\t dxy: %.4f" %track.dxy(),
print "\t dz: %.4f" %track.dz(),
print "\t nHits: %s" %track.numberOfValidHits(), "(%s P+ %s S)"%(track.hitPattern().numberOfValidPixelHits(),track.hitPattern().numberOfValidStripHits()),
print "\t algo: %s" %track.algoName(),
print "\t mva: %.3f" %mva
print "Event", i,
print "numTotal:", numTotal,
print "numLoose:", numLoose, "(%.1f %%)"%(float(numLoose)/numTotal*100),
print "numTight:", numTight, "(%.1f %%)"%(float(numTight)/numTotal*100),
print "numHighPurity:", numHighPurity, "(%.1f %%)"%(float(numHighPurity)/numTotal*100)
The C++-equivalent is hidden below.
C++ version
Update your
EDAnalyzeradding the following lines:To class declaration:
edm::EDGetTokenT<edm::View<float> > mvaValsToken_;To constructor:
, mvaValsToken_( consumes<edm::View<float> >(iConfig.getUntrackedParameter<edm::InputTag>("mvaValues", edm::InputTag("generalTracks", "MVAValues")) ) )Change your
analyzemethod to:std::cout << "Event " << indexEvent_ << std::endl; edm::Handle<edm::View<reco::Track> > trackHandle; iEvent.getByToken(tracksToken_, trackHandle); if ( !trackHandle.isValid() ) return; const auto numTotal = trackHandle->size(); edm::Handle<edm::View<float> > trackMVAstoreHandle; iEvent.getByToken(mvaValsToken_,trackMVAstoreHandle); if ( !trackMVAstoreHandle.isValid() ) return; auto numLoose = 0; auto numTight = 0; auto numHighPurity = 0; const edm::View<reco::Track>& tracks = *trackHandle; size_t iTrack = 0; for ( auto track : tracks ) { if (track.quality(track.qualityByName("loose")) ) ++numLoose; if (track.quality(track.qualityByName("tight")) ) ++numTight; if (track.quality(track.qualityByName("highPurity"))) ++numHighPurity; std::cout << " Track " << iTrack << " " << track.charge()/track.pt() << " " << track.phi() << " " << track.eta() << " " << track.dxy() << " " << track.dz() << track.chi2() << " " << track.ndof() << " " << track.numberOfValidHits() << " " << track.algoName() << " " << trackMVAstoreHandle->at(iTrack) << std::endl; iTrack++; } ++indexEvent_; std::cout << "Event " << indexEvent_ << " numTotal: " << numTotal << " numLoose: " << numLoose << " numTight: " << numTight << " numHighPurity: " << numHighPurity << std::endl;Go back to
TrackingShortExercize/and edit the CMSSW configuration file namedrun_cfg.py(emacs -nw run_cfg.py), adding the following line:process.PrintOutTracks.mvaValues = cms.untracked.InputTag("generalTracks","MVAValues")Now run the
analyzer:cmsRun run_cfg.pyThe
plugincan be found in/eos/uscms/store/user/cmsdas/2023/short_exercises/trackingvertexing/PrintOutTracks_MVA.ccTheCMSSW configfile can be found in/eos/uscms/store/user/cmsdas/2023/short_exercises/trackingvertexing/run_cfg_MVA.py
Question 1
Now prepare plots for the track variables discussed above, as in the example below (name this file
plot_track_quantities.pyand put it inTrackingShortExercize/). Compare the distributions of track-quality-related variables (number of pixel hits, track goodness of fit, …, which are given in input to MVA classifiers) between tracks passing thehighPurityandLoosequality flags. Do these distributions make sense to you?
Answer
import DataFormats.FWLite as fwlite import ROOT events = fwlite.Events("run321167_ZeroBias_AOD.root") tracks = fwlite.Handle("std::vector<reco::Track>") hist_pt = ROOT.TH1F("pt", "track pt; p_{T} [GeV]", 100, 0.0, 100.0) hist_eta = ROOT.TH1F("eta", "track eta; #eta", 60, -3.0, 3.0) hist_phi = ROOT.TH1F("phi", "track phi; #phi", 64, -3.2, 3.2) hist_loose_normChi2 = ROOT.TH1F("hist_loose_normChi2" , "norm. chi2; norm #chi^{2}" , 100, 0.0, 10.0) hist_loose_numPixelHits = ROOT.TH1F("hist_loose_numPixelHits", "pixel hits; # pixel hits" , 15, 0.0, 15.0) hist_loose_numValidHits = ROOT.TH1F("hist_loose_numValidHits", "valid hits; # valid hits" , 35, 0.0, 35.0) hist_loose_numTkLayers = ROOT.TH1F("hist_loose_numTkLayers" , "valid layers; # valid Tk layers" , 25, 0.0, 25.0) hist_highP_normChi2 = ROOT.TH1F("hist_highP_normChi2" , "norm. chi2; norm #chi^{2}" , 100, 0.0, 10.0) hist_highP_numPixelHits = ROOT.TH1F("hist_highP_numPixelHits", "pixel hits; # pixel hits" , 15, 0.0, 15.0) hist_highP_numValidHits = ROOT.TH1F("hist_highP_numValidHits", "valid hits; # valid hits" , 35, 0.0, 35.0) hist_highP_numTkLayers = ROOT.TH1F("hist_highP_numTkLayers" , "valid layers; # valid Tk layers" , 25, 0.0, 25.0) hist_highP_normChi2.SetLineColor(ROOT.kRed) hist_highP_numPixelHits.SetLineColor(ROOT.kRed) hist_highP_numValidHits.SetLineColor(ROOT.kRed) hist_highP_numTkLayers.SetLineColor(ROOT.kRed) for i, event in enumerate(events): event.getByLabel("generalTracks", tracks) for track in tracks.product(): hist_pt.Fill(track.pt()) hist_eta.Fill(track.eta()) hist_phi.Fill(track.phi()) if track.quality(track.qualityByName("loose")): hist_loose_normChi2 .Fill(track.normalizedChi2()) hist_loose_numPixelHits.Fill(track.hitPattern().numberOfValidPixelHits()) hist_loose_numValidHits.Fill(track.hitPattern().numberOfValidHits()) hist_loose_numTkLayers .Fill(track.hitPattern().trackerLayersWithMeasurement()) if track.quality(track.qualityByName("highPurity")): hist_highP_normChi2 .Fill(track.normalizedChi2()) hist_highP_numPixelHits.Fill(track.hitPattern().numberOfValidPixelHits()) hist_highP_numValidHits.Fill(track.hitPattern().numberOfValidHits()) hist_highP_numTkLayers .Fill(track.hitPattern().trackerLayersWithMeasurement()) if i > 500: break c = ROOT.TCanvas( "c", "c", 800, 800) hist_pt.Draw() c.SetLogy() c.SaveAs("track_pt.png") c.SetLogy(False) hist_eta.Draw() c.SaveAs("track_eta.png") hist_phi.Draw() c.SaveAs("track_phi.png") hist_highP_normChi2.DrawNormalized() hist_loose_normChi2.DrawNormalized('same') c.SaveAs("track_normChi2.png") hist_highP_numPixelHits.DrawNormalized() hist_loose_numPixelHits.DrawNormalized('same') c.SaveAs("track_nPixelHits.png") hist_highP_numValidHits.DrawNormalized() hist_loose_numValidHits.DrawNormalized('same') c.SaveAs("track_nValHits.png") hist_highP_numTkLayers.DrawNormalized() hist_loose_numTkLayers.DrawNormalized('same') c.SaveAs("track_nTkLayers.png")
- track_pt.png:
- track_eta.png:
- track_phi.png:
- track_normChi2.png:
- track_nPixelHits.png:
- track_nTkLayers.png:
- track_nValHits.png:






Track information in MiniAOD
There is no track collection stored in MiniAOD analogous to the generalTracks in AOD. Tracks associated to charged Particle Flow CandidatesPFCandidates are accessible directly from the packedPFCandidates collection for tracks with pT > 0.5 GeV. For tracks between 0.5 and 0.95 GeV the track information is stored with reduced precision. Tracks not associated with PF candidates are in the lostTracks collection if their pT is above 0.95 GeV or they are associated with a secondary vertex or a KS or Lambda candidate. However, for both the tracks associated to the PFCandidates and the lostTracks, the highQuality track selection is used. Tracks with lower quality are not available in MiniAOD at all. In addition, tracks in the lostTracks collection are required to have at least 8 hits of which at least one has to be a pixel hit.
In particular, the track information saved in the PFCandidates is the following:
Track information in PFCandidates collection
- the uncertainty on the impact parameter
dzError(),dxyError()- the number of layers with hits on the track
- the sub/det and layer of first hit of the track
- the
reco::Trackof the candidate is provided by thepseudoTrack()method, with the following information stored:
- the pT,eta and phi of the original track (if those are different from the one of the original
PFCandidate)- an approximate covariance matrix of the track state at the vertex
- approximate
hitPattern()andtrackerExpectedHitsInner()that yield the correct number of hits, pixel hits, layers and the information returned bylostInnerHits()- the track normalized chisquare (truncated to an integer)
- the
highPurityquality flag set, if the original track had it.
Consider that the packedPFCandidates collects both charged and neutral candidates, therefore before trying to access the track information it is important to ensure that the candidate is charged and has the track information correctly stored (track.hasTrackDetails()).
Question 2
Write a simple script
print-comparison.pythat reads a MiniAOD file and the AOD file and compare plots of the same variables we looked at before forHighPuritytracks. For the track pT distributuon, focus on the low pT region below 5 GeV. Can you see any (non-statistical) difference with the previosu plots? You can copy a MiniAOD file withxrdcp root://cmseos.fnal.gov//store/user/cmsdas/2023/short_exercises/trackingvertexing/run321167_ZeroBias_MINIAOD.root .
Answer
import DataFormats.FWLite as fwlite import ROOT ROOT.gROOT.SetBatch(True) events = fwlite.Events("run321167_ZeroBias_MINIAOD.root") eventsAOD = fwlite.Events("run321167_ZeroBias_AOD.root") tracks = fwlite.Handle("std::vector<pat::PackedCandidate>") losttracks = fwlite.Handle("std::vector<pat::PackedCandidate>") tracksAOD = fwlite.Handle("std::vector<reco::Track>") hist_pt = ROOT.TH1F("pt", "track pt; p_{T} [GeV]", 100, 0.0, 100.0) hist_lowPt = ROOT.TH1F("lowPt", "track pt; p_{T} [GeV]", 100, 0.0, 5.0) hist_eta = ROOT.TH1F("eta", "track eta; #eta", 60, -3.0, 3.0) hist_phi = ROOT.TH1F("phi", "track phi; #phi", 64, -3.2, 3.2) hist_normChi2 = ROOT.TH1F("hist_normChi2" , "norm. chi2; norm #chi^{2}" , 100, 0.0, 10.0) hist_numPixelHits = ROOT.TH1F("hist_numPixelHits", "pixel hits; # pixel hits" , 15, -0.5, 14.5) hist_numValidHits = ROOT.TH1F("hist_numValidHits", "valid hits; # valid hits" , 35, -0.5, 34.5) hist_numTkLayers = ROOT.TH1F("hist_numTkLayers" , "valid layers; # valid Tk layers" , 25, -0.5, 24.5) hist_pt_AOD = ROOT.TH1F("ptAOD", "track pt; p_{T} [GeV]", 100, 0.0, 100.0) hist_lowPt_AOD = ROOT.TH1F("lowPtAOD", "track pt; p_{T} [GeV]", 100, 0.0, 5.0) hist_eta_AOD = ROOT.TH1F("etaAOD", "track eta; #eta", 60, -3.0, 3.0) hist_phi_AOD = ROOT.TH1F("phiAOD", "track phi; #phi", 64, -3.2, 3.2) hist_normChi2_AOD = ROOT.TH1F("hist_normChi2AOD" , "norm. chi2; norm #chi^{2}" , 100, 0.0, 10.0) hist_numPixelHits_AOD = ROOT.TH1F("hist_numPixelHitsAOD", "pixel hits; # pixel hits" , 15, -0.5, 14.5) hist_numValidHits_AOD = ROOT.TH1F("hist_numValidHitsAOD", "valid hits; # valid hits" , 35, -0.5, 34.5) hist_numTkLayers_AOD = ROOT.TH1F("hist_numTkLayersAOD" , "valid layers; # valid Tk layers" , 25, -0.5, 24.5) hist_pt_AOD.SetLineColor(ROOT.kRed) hist_lowPt_AOD.SetLineColor(ROOT.kRed) hist_eta_AOD.SetLineColor(ROOT.kRed) hist_phi_AOD.SetLineColor(ROOT.kRed) hist_normChi2_AOD.SetLineColor(ROOT.kRed) hist_numPixelHits_AOD.SetLineColor(ROOT.kRed) hist_numValidHits_AOD.SetLineColor(ROOT.kRed) hist_numTkLayers_AOD.SetLineColor(ROOT.kRed) for i, event in enumerate(events): event.getByLabel("packedPFCandidates", "", tracks) event.getByLabel("lostTracks", "", losttracks) alltracks = [track for track in tracks.product()] alltracks += [track for track in losttracks.product()] for track in alltracks : if (not track.hasTrackDetails() or track.charge() == 0 ): continue if not track.trackHighPurity(): continue hist_pt.Fill(track.pt()) hist_lowPt.Fill(track.pt()) hist_eta.Fill(track.eta()) hist_phi.Fill(track.phi()) hist_normChi2 .Fill(track.pseudoTrack().normalizedChi2()) hist_numPixelHits.Fill(track.numberOfPixelHits()) hist_numValidHits.Fill(track.pseudoTrack().hitPattern().numberOfValidHits()) hist_numTkLayers .Fill(track.pseudoTrack().hitPattern().trackerLayersWithMeasurement()) if i > 1000: break for i, event in enumerate(eventsAOD): event.getByLabel("generalTracks", tracksAOD) for j, track in enumerate(tracksAOD.product()) : if not track.quality(track.qualityByName("highPurity")): continue hist_pt_AOD.Fill(track.pt()) hist_lowPt_AOD.Fill(track.pt()) hist_eta_AOD.Fill(track.eta()) hist_phi_AOD.Fill(track.phi()) hist_normChi2_AOD .Fill(track.normalizedChi2()) hist_numPixelHits_AOD.Fill(track.hitPattern().numberOfValidPixelHits()) hist_numValidHits_AOD.Fill(track.hitPattern().numberOfValidHits()) hist_numTkLayers_AOD .Fill(track.hitPattern().trackerLayersWithMeasurement()) if i > 1000: break c = ROOT.TCanvas( "c", "c", 800, 800) hist_pt.Draw() hist_pt_AOD.Draw("same") c.SetLogy() c.SaveAs("track_pt_miniaod.png") hist_lowPt_AOD.Draw() hist_lowPt.Draw("same") c.SetLogy() c.SaveAs("track_lowPt_miniaod.png") c.SetLogy(False) hist_eta_AOD.Draw() hist_eta.Draw("same") c.SaveAs("track_eta_miniaod.png") hist_phi_AOD.Draw() hist_phi.Draw("same") c.SaveAs("track_phi_miniaod.png") hist_normChi2_AOD.Draw() hist_normChi2.Draw("same") c.SaveAs("track_normChi2_miniaod.png") hist_numPixelHits_AOD.Draw() hist_numPixelHits.Draw("same") c.SaveAs("track_nPixelHits_miniaod.png") hist_numValidHits_AOD.Draw() hist_numValidHits.Draw("same") c.SaveAs("track_nValHits_miniaod.png") hist_numTkLayers_AOD.Draw() hist_numTkLayers.Draw("same") c.SaveAs("track_nTkLayers_miniaod.png")
Key Points
The pre-selection of tracks to
HighPurityin MiniAOD also affects the distribution of the track quality parameters.All tracks are stored in the
generalTrackscollection in AOD.In MiniAOD they are accessible in a less straightforward way (
packedPFCandidates,lostTrackscollection) and not all tracks are available!